각 언어에 맞는 폰트를 사용해야 하는 이유(특히 한국어·중국어·일본어에서)
현재 전 세계 문자의 전산화를 담당하는 표준 코드 체계는 유니코드(Unicode)이다. 유니코드의 표준을 규율하는 민간 단체인 유니코드 콘소시엄에서는 유니코드를 다음과 같이 소개하고 있다.
유니코드에 대해 ?
어떤 플랫폼,
어떤 프로그램,
어떤 언어에도 상관없이
유니코드는 모든 문자에 대해 고유 번호를 제공합니다.
기본적으로 컴퓨터는 숫자만 처리합니다. 글자나 다른 문자에도 숫자를 지정하여 저장합니다. 유니코드가 개발되기 전에는 이러한 숫자를 지정하기 위해 수백 가지의 다른 기호화 시스템을 사용했습니다. 단일 기호화 방법으로는 모든 문자를 포함할 수 없었습니다. 예를 들어 유럽 연합에서만 보더라도 모든 각 나라별 언어를 처리하려면 여러 개의 다른 기호화 방법이 필요합니다. 영어와 같은 단일 언어의 경우도 공통적으로 사용되는 모든 글자, 문장 부호 및 테크니컬 기호에 맞는 단일 기호화 방법을 갖고 있지 못하였습니다.
이러한 기호화 시스템은 또한 다른 기호화 시스템과 충돌합니다. 즉 두 가지 기호화 방법이 두 개의 다른 문자에 대해 같은 번호를 사용하거나 같은 문자에 대해 다른 번호를 사용할 수 있습니다. 주어진 모든 컴퓨터(특히 서버)는 서로 다른 여러 가지 기호화 방법을 지원해야 합니다. 그러나, 데이터를 서로 다른 기호화 방법이나 플랫폼 간에 전달할 때마다 그 데이터는 항상 손상의 위험을 겪게 됩니다.
유니코드로 모든 것을 해결할 수 있습니다!
유니코드는 사용 중인 플랫폼, 프로그램, 언어에 관계없이 문자마다 고유한 숫자를 제공합니다. 유니코드 표준은 Apple, HP, IBM, JustSystem, Microsoft, Oracle, SAP, Sun, Sybase, Unisys 및 기타 여러 회사와 같은 업계 선두주자에 의해 채택되었습니다. 유니코드는 XML, Java, ECMAScript(JavaScript), LDAP, CORBA 3.0, WML 등과 같이 현재 널리 사용되는 표준에서 필요하며 이는 ISO/IEC 10646을 구현하는 공식적인 방법입니다. 이는 많은 운영 체제, 요즘 사용되는 모든 브라우저 및 기타 많은 제품에서 지원됩니다. 유니코드 표준의 부상과 이를 지원하는 도구의 가용성은 최근 전 세계에 불고 있는 기술 경향에서 가장 중요한 부분을 차지하고 있습니다.
유니코드를 클라이언트-서버 또는 다중-연결 응용 프로그램과 웹 사이트에 통합하면 레거시 문자 세트 사용에 있어서 상당한 비용 절감 효과가 나타납니다. 유니코드를 통해 리엔지니어링 없이 다중 플랫폼, 언어 및 국가 간에 단일 소프트웨어 플랫폼 또는 단일 웹 사이트를 목표로 삼을 수 있습니다. 이를 사용하면 데이터를 손상 없이 여러 시스템을 통해 전송할 수 있습니다.
‘이론상으로는’ 단일한 기호화 시스템으로 전 세계 모든 언어의 문자들을 표현한다는 얘기이다. 이론상으로는. 그런데 유니코드를 만드는 과정에서 한자(漢字) 등의 이체자(異體字, ideographic variants)들을 제대로 구분하지 못하는 문제가 발생했다.
한자의 경우 뜻(훈·訓)과 소리(음·音)은 같은데 글자의 모양(형·形)이 다른 글자들이 무수히 많이 존재한다. 이런 글자들을 이체자라고 한다. 예를 들어 ‘나라 국’ 자의 경우 정체자인 國, 속자(俗字)·약자(略字)에 속하는 国 등 여러 이체자가 존재한다(이것 말고도 아주 많다. 여기서는 대표적으로 많이 쓰이는 두 개만 제시했다). 유니코드에서는 國과 国처럼 모양이 확연히 다른 이체자들은 다른 코드를 부여해서 구분을 하고 있는데 이런 경우 별 문제가 없다. 그런데 유니코드 콘소시엄은 미세한 차이가 있는 이체자들은 그냥 차이를 무시하고 한 코드로 부여해 놓아 버렸다. 여기서 문제가 발생했다.
현재 한자 문화권에서는 국가마다 한자 자형이 다르다. 물론 정체자/간체자나 구자체/신자체 같은 차이도 있지만 그보다 훨씬 미세한 차이를 지닌 이체자들이 각국에서 쓰이고 있다. 한국이냐 중국(본토)냐 대만이냐 홍콩이냐 일본이냐… 등등 나라/지역에 따라 조금씩 다르다. 다음은 그 예이다. 
유니코드 내에 같은 코드를 할당 받은 문자임에도 형태가 다른 예를 생각나는대로 위 표에 정리해 보았다. 한국어는 한국의 폰트를, 중국어(간체)는 중국 본토의 폰트를, 중국어(정체)는 대만의 폰트를, 일본어는 일본의 폰트를 써야 그 글을 읽는 독자들의 이질감·위화감을 줄일 수 있다. 예를 들어 일본 사람들이 볼 일본어 문장에다가 한국어 폰트를 사용해서 評(평론할 평) 자를 써 놓으면 일본 사람들이 읽을 줄은 알지만 글자 모양이 이상하다고 여긴다. 또 한국이나 대만 사람들한테 龜(거북 구) 자를 보여주는데 위 표에 나와 있듯 중국 본토의 폰트를 사용해서 출력해 주면 글씨가 왜 이렇게 이상하게 생겼냐고 따질 것이다.
이런 문제는 애초에 유니코드 콘소시엄이 유니코드에 한자를 정리할 때 너무 무신경하게 미세한 이체자를 구분하지 않아 생긴 문제다. 아무튼 유니코드 콘소시엄의 무신경한 처사 때문에 우리는 컴퓨터로 여러 언어를 입력할 때 폰트까지 고려해야 하는 상황에 놓여 있다. 사실 유니코드의 이체자 문제는 동아시아 언어·문자에서만 나타나는 건 아니다. 다음과 같은 사례도 있다. 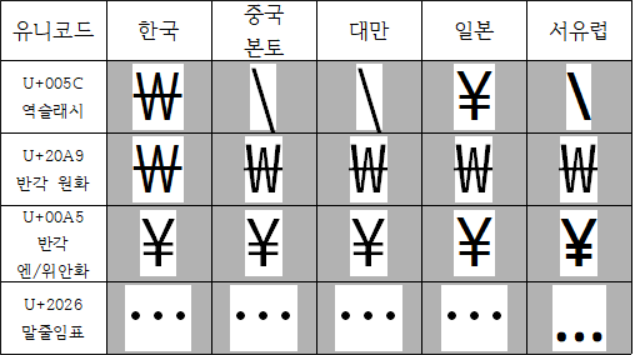
반각 역슬래시(\, U+005C)는 원래 용도와 달리 한국어나 일본어 폰트에서 자국의 화폐 기호 형태로 렌더링하는 경우가 흔하다. 물론 모든 폰트가 그런 건 아니지만 상당히 많은 폰트가 이러고 있다. 원칙대로라면 위 표에 나와 있듯이 유니코드에 들어가 있는 반각 원화(₩, U+20A9)와 반각 엔/위안화(¥, U+20A9)를 쓰는 게 맞지만 한국과 일본에서는 잘 안 지켜지고 있다. 어쨌든 반각 역슬래시(\, U+005C)는 한국과 일본에서 각각 나름의 이체자가 쓰이는 셈이다. 그리고 말줄임표(…, U+2026)는 동아시아의 폰트는 대개 가운뎃점(·) 세 개를 연달아 찍은 형태로 렌더링하지만 서유럽 언어용 폰트는 그냥 온점(.) 세 개를 연달아 찍은 형태로 렌더링하는 경우가 많다. 여기서도 동아시아와 서양 간 이체자가 발생한 경우라고 볼 수 있겠다.
그리고 특정 국가라기보다는 폰트마다 렌더링이 다른 문자도 있다. 다음이 그 예이다. 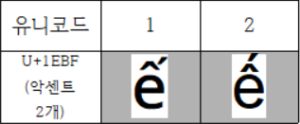 위 글자는 베트남어에서 사용되는 문자인데, 폰트에 따라서 맨 위의 악센트가 찍히는 위치가 조금씩 다르다(베트남에서 선호되는 글자는 2번인 듯하다. 베트남어를 아시는 분의 확인 바란다). 아무튼 이거 말고도 유니코드에는 이체자 문제가 아주 많다. 일단 컴퓨터로 외국어를 입력할 때 가능하면 폰트까지 고려하는 습관을 들이는 게 좋다고 기억해 두면 좋다.
위 글자는 베트남어에서 사용되는 문자인데, 폰트에 따라서 맨 위의 악센트가 찍히는 위치가 조금씩 다르다(베트남에서 선호되는 글자는 2번인 듯하다. 베트남어를 아시는 분의 확인 바란다). 아무튼 이거 말고도 유니코드에는 이체자 문제가 아주 많다. 일단 컴퓨터로 외국어를 입력할 때 가능하면 폰트까지 고려하는 습관을 들이는 게 좋다고 기억해 두면 좋다.
추신: 유니코드 콘소시엄에서도 동아시아 국가들의 반발에 하도 시달렸는지 현재는 뒤늦게 폰트가 아닌 문자 코드만으로 이체자를 구분하는 기술을 도입하고는 있다. Ideographic Variation Sequence(IVS)라는 눈에 보이지 않는 문자를 한자 뒤에 삽입하면 적절한 이체자로 렌더링하게 해주도록 하는 건데 아직 이 방식을 완전히 지원하는 폰트가 많지 않다. IVS가 일반화될 때까지는 그냥 언어에 따라 일일이 폰트를 다르게 지정해 주는 게 낫겠다. 참고로 유니코드의 한자 이체자 정보는 한 일본인이 개설한 GlyphWiki라는 사이트를 이용하면 편리하다.
추가: 웹페이지(HTML, CSS)에서 언어별 폰트를 다르게 지정하는 방법은 이 글을 참고하도록 하자.
 이 저작물은 크리에이티브 커먼즈 저작자표시-변경금지 4.0 국제 라이선스에 따라 이용할 수 있습니다.
이 저작물은 크리에이티브 커먼즈 저작자표시-변경금지 4.0 국제 라이선스에 따라 이용할 수 있습니다.